2018 Duolingo Shared Task on Second Language Acquisition Modeling (SLAM)
This challenge is in conjunction with the 13th BEA Workshop and NAACL-HLT 2018 conference.
Introduction
As educational apps increase in popularity, vast amounts of student learning data become available, which can and should be used to drive personalized instruction. While there have been some recent advances in domains like mathematics, modeling second language acquisition (SLA) is more nuanced, involving the interaction of lexical knowledge, morpho-syntactic processing, and other skills. Furthermore, most work in NLP for second language (L2) learners has focused on intermediate-to-advanced students of English in assessment settings. Much less work has been done involving beginners, learners of languages other than English, or study over time.
This task aims to forge new territory by utilizing student trace data from users of Duolingo, the world's most popular online language-learning platform. Participating teams are provided with transcripts from millions of exercises completed by thousands of students over their first 30 days of learning on Duolingo. These transcripts are annotated for token (word) level mistakes, and the task is to predict what mistakes each learner will make in the future.
Novel and interesting research opportunities in this task:
- There will be three (3) tracks for learners of English, Spanish, and French. Teams are encouraged to explore features which generalize across all three languages.
- Anonymized user IDs and time data will be provided. This allows teams to explore various personalized, adaptive SLA modeling approaches.
- The sequential nature of the data also allows teams to model language learning (and forgetting) over time.
By accurately modeling student mistake patterns, we hope this task will shed light on both (1) the inherent nature of L2 learning, and (2) effective ML/NLP engineering strategies to build personalized adaptive learning systems.
Official Results
(Updated April 23, 2018). The task attracted strong participation from 15 teams (11 that submitted system papers), representing both academia and industry from various fields including cognitive science, linguistics, and machine learning. The best systems were able to improve upon a simple logistic regression baseline by 12%. Check out the organizers' task overview paper and system results below.
Read the 2018 SLAM Task Overview Paper »
| English | Spanish | French | Avg. | ||||
|---|---|---|---|---|---|---|---|
| Team | AUC | F1 | AUC | F1 | AUC | F1 | Rank |
| SanaLabs ♢♣ | 0.861 | 0.561 | 0.838 | 0.530 | 0.857 | 0.573 | 1.0 |
| singsound ♢ | 0.861 | 0.559 | 0.835 | 0.524 | 0.854 | 0.569 | 1.7 |
| NYU ♣‡ | 0.859 | 0.468 | 0.835 | 0.420 | 0.854 | 0.493 | 2.3 |
| TMU ♢‡ | 0.848 | 0.476 | 0.824 | 0.439 | 0.839 | 0.502 | 4.3 |
| CECL ‡ | 0.846 | 0.414 | 0.818 | 0.390 | 0.843 | 0.487 | 4.7 |
| Cambridge ♢ | 0.841 | 0.479 | 0.807 | 0.435 | 0.835 | 0.508 | 6.0 |
| UCSD ♣ | 0.829 | 0.424 | 0.803 | 0.375 | 0.823 | 0.442 | 7.0 |
| LambdaLab ♣ | 0.821 | 0.389 | 0.801 | 0.344 | 0.815 | 0.415 | 7.6 |
| Grotoco | 0.817 | 0.462 | 0.791 | 0.452 | 0.813 | 0.502 | 9.0 |
| nihalnayak | 0.821 | 0.376 | 0.790 | 0.338 | 0.811 | 0.431 | 9.0 |
| jilljenn | 0.815 | 0.329 | 0.788 | 0.306 | 0.809 | 0.406 | 10.7 |
| SLAM_baseline | 0.774 | 0.190 | 0.746 | 0.175 | 0.771 | 0.281 | 14.7 |
A summary of key findings from the organizers' meta-analyses are:
- Choice of learning algorithm, at least for this formulation of the task, appears to be more important than clever feature engineering
- In particular, recurrent neural networks (♢) and decision tree ensembles (♣) performed particularly well
- Teams that used a multitask framework (‡)—that is, a unified model across all three tracks—also did well
- Morpho-syntactic features (part-of-speech, dependency parses, etc.) tended not to be useful, possibly due to the systematic errors in state-of-the-art parsers, making them hurt more than help
- Popular novel, team-engineered features included: word corpus frequency, cognates, vector-space embeddings, stem/root/lemma, and features that capture user/word history and spaced repetition
- These psychologically-motivated features did not appear to help as much as learning algorithm choice, but some of that may be due to limitations in the SLAM task data; it would be interesting to re-visit these ideas with a more linguistically diverse and longitudinal corpus in the future
Important Dates
| June 05, 2018 | Workshop at NAACL-HLT in New Orleans! (Link, Registration) |
| April 16, 2018 | Camera-ready system papers due (Instructions) |
| April 10, 2018 | System paper reviews returned |
| March 28, 2018 | Draft system papers due |
| March 21, 2018 | Final results announcement |
| March 19, 2018 | Final predictions deadline (CodaLab) |
| March 9, 2018 | Data release (phase 2): blind TEST set (Dataverse) |
| January 10, 2018 | Data release (phase 1): TRAIN and DEV sets (Dataverse) |
Mailing List & Organizers
We have created a Google Group to foster discussion and answer questions related to this task:
The task organizers are:
- Burr Settles (Duolingo)
- Chris Brust (Duolingo)
- Erin Gustafson (Duolingo)
- Masato Hagiwara (Duolingo)
- Bozena Pajak (Duolingo)
- Joseph Rollinson (Duolingo)
- Hideki Shima (Duolingo)
- Nitin Madnani (ETS)
Task Definition & Data
Background
Duolingo is a free, award-winning, online language learning platform. Since launching in 2012, more than 200 million students from all over the world have enrolled in one of Duolingo's 80+ game-like language courses, via the website or mobile apps. For comparison, that is more than the total number of students in the entire U.S. school system.
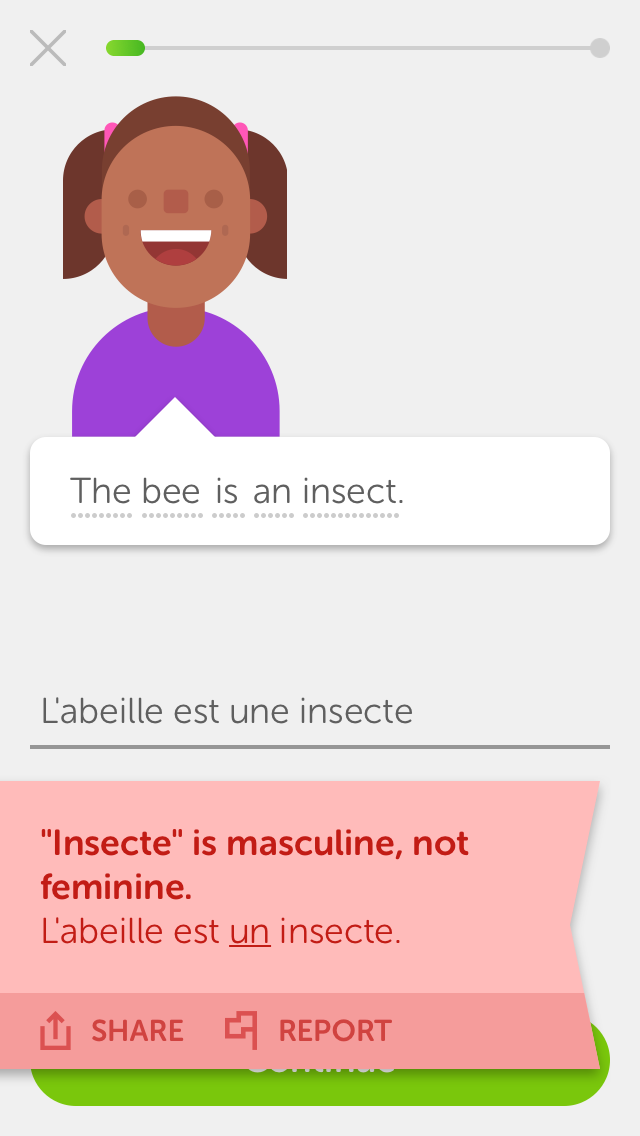
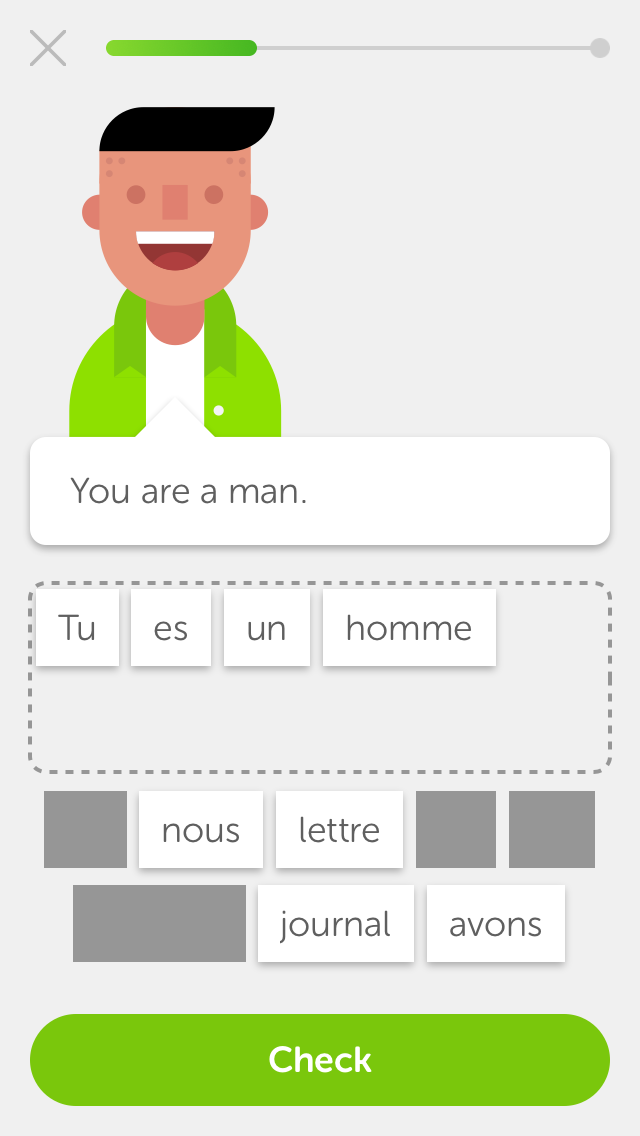
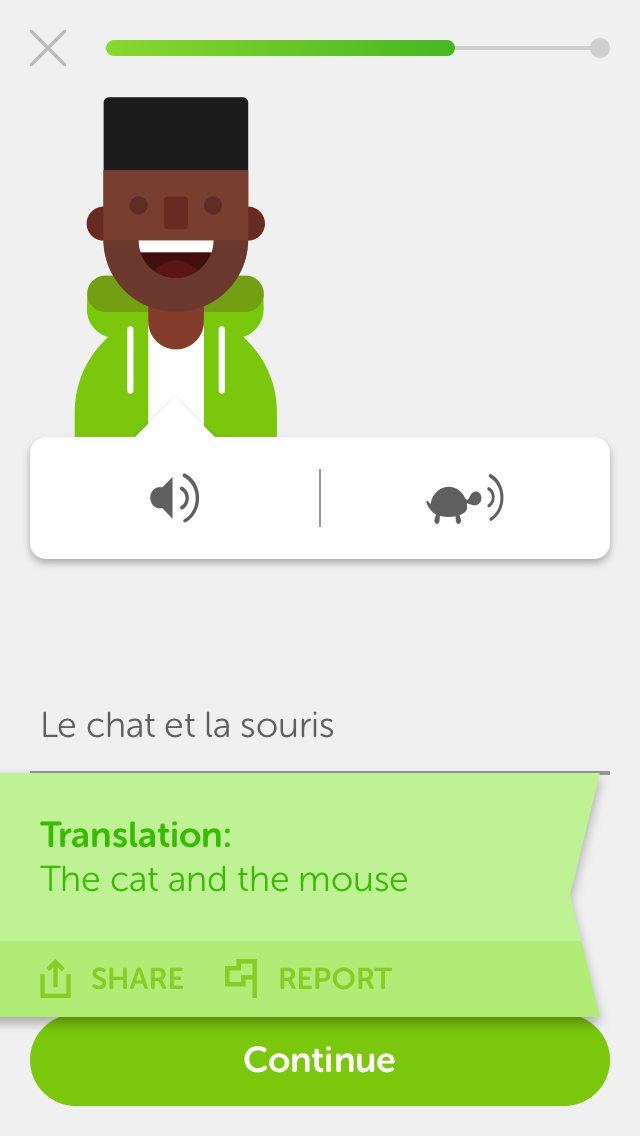
While the Duolingo app includes several interactive exercise formats designed to develop different language skills, this shared task will focus on the three (3) formats linked to written production. The figure below illustrates these formats for an English speaker who is learning French (using the iPhone app).
reverse_translate
reverse_tap
listen
Exercise (a) is a reverse_translate item, where
students read a prompt written in the language they know (e.g.,
their native language), and translate it into the language they are
learning (L2). Exercise (b) is a reverse_tap item, an
easier version of this format where students construct an answer
from a bank of words and distractors. Exercise (c) is a
listen item, requiring students to listen to an
utterance in the L2 they are learning, and transcribe it.
Since each exercise can have multiple correct answers (up to thousands each, due to synonyms, homophones, or ambiguities in number, tense, formality, etc.), Duolingo uses FSTs to align the student's answer to the most similar correct answer in the exercise's very large set of acceptable answers. Figure (a) above, for example, shows example corrective feedback based on such an alignment.
Prediction Task
In these exercises, students construct answers in the L2 they are learning, and make various mistakes along the way. The goal of this task is to predict future mistakes that learners of English, Spanish, and French will make based on a history of the mistakes they have made in the past. More specifically, the data set contains more than 2 million tokens (words) from answers submitted by more than 6,000 Duolingo students over the course of their first 30 days.
We provide token-level labels and dependency parses for the most similar correct answer to each student submission. For example, the figure below shows a parse tree for the correct answer, the aligned student's answer, and the resulting labels (for a Spanish speaker learning English):

This student seems to be struggling with "my", "mother", and "father." Perhaps she has trouble with possessive pronouns? Or the orthography of English "th" sounds? A successful SLA modeling system should be able to pick up on these trends, predicting which words give the student trouble in a personalized way (that evolves over time).
Most tokens (about 83%) are perfect matches and are given the label
0 for "OK." Tokens that are missing or spelled
incorrectly (ignoring capitalization, punctuation, and accents) are
given the label 1 denoting a mistake.
Note: For this task, we provide labels but not actual student responses. We intend to release a more comprehensive version of the data set after the workshop, including student answers and other metadata.
Data Format
The data format is inspired by the Universal Dependencies CoNNL-U format. Each student exercise is represented by a group of lines separated by a blank line: one token per line prepended with exercise-level metadata. Here are some examples (you may need to scroll horizontally to see all columns):
# user:D2inSf5+ countries:MX days:1.793 client:web session:lesson format:reverse_translate time:16 8rgJEAPw1001 She PRON Case=Nom|Gender=Fem|Number=Sing|Person=3|PronType=Prs|fPOS=PRON++PRP nsubj 4 0 8rgJEAPw1002 is VERB Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin|fPOS=VERB++VBZ cop 4 0 8rgJEAPw1003 my PRON Number=Sing|Person=1|Poss=Yes|PronType=Prs|fPOS=PRON++PRP$ nmod:poss 4 1 8rgJEAPw1004 mother NOUN Degree=Pos|fPOS=ADJ++JJ ROOT 0 1 8rgJEAPw1005 and CONJ fPOS=CONJ++CC cc 4 0 8rgJEAPw1006 he PRON Case=Nom|Gender=Masc|Number=Sing|Person=3|PronType=Prs|fPOS=PRON++PRP nsubj 9 0 8rgJEAPw1007 is VERB Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin|fPOS=VERB++VBZ cop 9 0 8rgJEAPw1008 my PRON Number=Sing|Person=1|Poss=Yes|PronType=Prs|fPOS=PRON++PRP$ nmod:poss 9 1 8rgJEAPw1009 father NOUN Number=Sing|fPOS=NOUN++NN conj 4 1 # user:D2inSf5+ countries:MX days:2.689 client:web session:practice format:reverse_translate time:6 oMGsnnH/0101 When ADV PronType=Int|fPOS=ADV++WRB advmod 4 1 oMGsnnH/0102 can AUX VerbForm=Fin|fPOS=AUX++MD aux 4 0 oMGsnnH/0103 I PRON Case=Nom|Number=Sing|Person=1|PronType=Prs|fPOS=PRON++PRP nsubj 4 1 oMGsnnH/0104 help VERB VerbForm=Inf|fPOS=VERB++VB ROOT 0 0
The first line of each exercise group (beginning with
#) contains the following metadata about the student,
session, and exercise:
-
user: a B64 encoded, 8-digit, anonymized, unique identifier for each student (may include/or+characters) -
countries: a pipe (|) delimited list of 2-character country codes from which this user has done exercises -
days: the number of days since the student started learning this language on Duolingo -
client: the student's device platform (one of:android,ios, orweb) -
session: the session type (one of:lesson,practice, ortest; explanation below) -
format: the exercise format (one of:reverse_translate,reverse_tap, orlisten; see figures above) -
time: the amount of time (in seconds) it took for the student to construct and submit their whole answer (note: for some exercises, this can benulldue to data logging issues)
These fields are separated by whitespaces on the same line, and
key:value pairs are denoted with a colon (:).
The lesson sessions (about 77% of the data set) are
where new words or concepts are introduced, although lessons also
include a lot previously-learned material (e.g., each exercise tries
to introduce only one new word or tense, so all other tokens should
have been seen by the student before). The
practice sessions (22%) should contain only
previously-seen words and concepts. The test sessions
(1%) are quizzes that allow a student "skip" a particular skill unit
of the curriculum (i.e., the student may have never seen this
content before in the Duolingo app, but may well have had prior
knowledge before starting the course).
The remaining lines in each exercise group represent each token (word) in the correct answer that is most similar to the student's answer, one token per line, arranged into seven (7) columns separated by whitespaces:
- A Unique 12-digit ID for each token instance: the first 8 digits are a B64-encoded ID representing the session, the next 2 digits denote the index of this exercise within the session, and the last 2 digits denote the index of the token (word) in this exercise
- The token (word)
- Part of speech in Universal Dependencies (UD) format
- Morphological features in UD format
- Dependency edge label in UD format
- Dependency edge head in UD format (this corresponds to the last 1-2 digits of the ID in the first column)
-
The label to be predicted (
0or1)
All dependency features (columns 3-6) are generated by the Google SyntaxNet dependency parser using the language-agnostic Universal Dependencies tagset. (In other words, these morpho-syntactic features should be comparable across all three tracks in the shared task. Note that SyntaxNet isn't perfect, so parse errors may occur.)
The only difference between TRAIN and DEV/TEST set formats is that the final column (labels) will be omitted from the DEV/TEST set files. The first column (unique instance IDs) are also used for the submission output format.
time field. These occur in the TRAIN set for
en_es (17 cases), and the DEV sets for
en_es (2 cases) and es_en (1 case). These
logging errors are due to client-side browser bugs on web (i.e., not
iOS or Android apps) and race conditions caused by slow internet
connections. If you plan on using response times as part of your
modeling, we advise you to check for negative values and treat them
as null.
Three Language Tracks
The data for this task are organized into three tracks:
-
en_es— English learners (who already speak Spanish) -
es_en— Spanish learners (who already speak English) -
fr_en— French learners (who already speak English)
The TRAIN, DEV, and TEST sets will be written to separate files for each of these tracks. Each track will have its own leaderboard for predictions (see "Submission & Evaluation" section below). Some teams may want to focus on a particular track/language, however, participation in all three tracks is encouraged!
Data Release Schedule
Data for the task will be released in two phases:
- Phase 1 (8 weeks): TRAIN and DEV sets for "offline" development and experimentation. This release includes example code for a baseline system and an evaluation script in Python.
- Phase 2 (10 days): TEST set, which does not include labels. Evaluations will be conducted using the CodaLab online interface (see the "Submission & Evaluation" below for more details).
After the workshop, there will be an updated third release of the data (including labels and additional metadata for all splits) to support ongoing research in the area of SLA modeling.
The track data sets (data_*.tar.gz) and baseline code
(starter_code.tar.gz) are hosted on Dataverse:
Download Data & Baseline Code »
Submission & Evaluation
Metrics
The primary evaluation metric will be area under the
ROC curve
(AUC).
F1 score (with
a threshold of 0.5) will also be reported and analyzed.
As such, some teams may wish to attempt combined classification and
ranking methods. Note that the label 1 (denoting a
mistake) is considered the "positive" class for both metrics.
The official AUC and F1 metrics (plus a few others) are implemented
in eval.py alongside the baseline code.
Open Feature Engineering
This is an "open" evaluation, meaning teams are allowed (and encouraged!) to experiment with additional features beyond those provided with the data release. Features that lead to interpretable/actionable insights about individual learning (e.g., "this user struggles with adjective-noun word order") are particularly encouraged.
See the "Tips & Related Work" section below for some ideas of where to start with additional feature engineering. Teams should thoroughly describe any new features in their system papers for the workshop proceedings (see below), and/or release source code to support replication and ongoing research.
Evaluation: CodaLab
All system submissions and evaluation will be done via CodaLab.
To participate, follow these steps:
- Create an account at https://competitions.codalab.org (one account per team)
- Register for the SLAM competition here: https://competitions.codalab.org/competitions/18491
- Go to the "Participate" tab and click the "Register" button
- Once your team is registered, feel free to share the login details among your collaborators
Go to the CodaLab Competition »
Leaderboards
Your CodaLab evaluation results will appear on the shared task leaderboards under the "Results" tab. There is a separate leaderboard for each track. These report three metrics: AUC, F1, and also average log-loss.
To submit your team's predictions:
- Go to the "Participate" tab in CodaLab and click "Submit / View Results"
-
Upload a single
.zipcontaining prediction files for all the tracks your team is participating in
The grading script will automatically look for and evaluate files
for each track separately (by matching filenames against
en_es, es_en, or fr_en). For
example, your submission might contain the following structure:
my_test_submission_file.zip test.en_es.preds test.es_en.preds test.fr_en.preds
Prediction files should be in the "root" of the
.zip file, (that is, not in a subdirectory). Any files
that do not match the three expected track IDs will be ignored, and
if multiple files match (e.g., two en_es files), only
one of them will be evaluated.
Be careful to include only one prediction file per track! If
you are not participating in all three tracks, simply omit any
irrelevant prediction file(s) from the .zip archive.
You will be able to submit up to 10 total runs (up to 2 runs per day) during the 10-day TEST Phase. This will enable you to evaluate a few variants of your system or parameters, if you so desire. Evaluation results should be available for review within a few seconds.
Prediction Format
The submission file format is similar to those generated by the provided baseline model.
Submission should be a whitespace-delimited file with 1 row per
instance and no header. The first column must be the instance ID,
and the last column must be the prediction (consistent with the
first and last columns of the TRAIN data). Other columns, blank
lines, or lines beginning with # will be ignored.
Values in the prediction column should be in the range
[0.0, 1.0], and will be interpreted as "the probability
that the student makes a mistake," i.e., p(mistake|instance). The
prediction files for all tracks (up to three) must be placed in a
single .zip archive prior to submission.
Here is an example prediction file (only the first few lines are shown):
DRihrVmh0901 0.025 DRihrVmh0902 0.08 DRihrVmh0903 0.454 DRihrVmh0904 0.044 TOeLHxLS0401 0.067 TOeLHxLS0402 0.03 TOeLHxLS0403 0.806 TOeLHxLS0404 0.066 xqtN1I5c0901 0 xqtN1I5c0902 0.074 xqtN1I5c0903 0.053 xqtN1I5c0904 0.016 ...
Your predictions should follow this format.
System Papers & Citation Details
All teams are expected to submit a system paper describing their approach and results, to be published in the workshop proceedings and available through the ACL Anthology website. Please do so even if you are unable to travel to the BEA Workshop at the NAACL-HLT conference in June 2018.
Note that we are interested not only in top-performing systems (i.e., metrics), but also meaningful findings (i.e., insights for language and/or learning). Teams are encouraged to focus on both in their write-ups!
Papers should follow the the NAACL 2018 submission guidelines. Teams are invited to submit a full paper (4-8 pages of content, with unlimited pages for references). We recommend using the official style templates:
All submissions must in PDF format and should not be anonymized. Supplementary files (hyperparameter settings, external features or ablation results too extensive to fit in the main paper, etc.) are also welcome, so long as they follow the NAACL 2018 Guidelines. Final camera ready versions of accepted papers will be given up to one additional page of content (9 pages plus references) to address reviewer comments. Papers must include the following citation:
B. Settles, C. Brust, E. Gustafson, M. Hagiwara, and N. Madnani. 2018. Second Language Acquisition Modeling. In Proceedings of the NAACL-HLT Workshop on Innovative Use of NLP for Building Educational Applications (BEA). ACL.
@inproceedings{slam18,
Author = {B. Settles and C. Brust and E. Gustafson and M. Hagiwara and N. Madnani},
Booktitle = {Proceedings of the NAACL-HLT Workshop on Innovative Use of NLP for Building Educational Applications (BEA)},
Publisher = {ACL},
Title = {Second Language Acquisition Modeling},
Year = {2018}}
We will use the START conference system to manage submissions via, the BEA Workshop. Under "Submission Category" be sure to select "SLAM Shared Task Paper" (see screenshot below):

Submit your paper through START »
\aclfinalcopy line is uncommented, and that the final
PDF includes author names and contact information.
Tips & Related Work
SLA modeling is a rich and complex task, and presents an opportunity to synthesize methods from various subfields in computational linguistics, machine learning, educational data mining, and psychometrics.
This page contains a few suggestions and pointers to related research areas, which could be useful for feature engineering or other modeling decisions.
Item Response Theory (IRT)
- IRT models are common in intelligent tutoring systems (and standardized testing). In its simplest form (i.e., the Rasch model), IRT is simply logistic regression with two weights: one representing the student's ability, and the other representing the difficulty of the exercise or test item. There are more complex variants as well.
- Additive and Conjunctive Factor Models (Cen et al., 2008) extend IRT to multiple interacting "knowledge components" — examples for SLA modeling could be lexical, morphological, or syntactic features. Hint: the baseline model included with the shared task data is a sort of additive factor model (AFM): a logistic regression that includes both user ID weights ("latent ability") and token feature weights ("knowledge components").
- There are also IRT models that account for speed-accuracy tradeoffs (Maris & van der Maas, 2012). The shared task data includes exercise-level response times, so some of these techniques might be interesting.
Modeling Learning & Forgetting Over Time
- Bayesian Knowledge Tracing (BKT) is another common tutoring system algorithm. It is essentially a hidden Markov model (HMM) that tries to estimate the point at which a student has "learned" a concept. Deep Knowledge Tracing (DKT) is a more recent implementation of the idea using recurrent neural networks (RNNs). Note that these methods only capture short-term learning, not long-term forgetting.
- Half-life Regression (Settles & Meeder, 2016) is a machine-learned model of the exponential "forgetting curve."
- 100 Years of Forgetting (Rubin & Wenzel, 1996) is an excellent survey paper exploring various different forgetting curves. Half-life regression can be seen as a generalization of the exponential forgetting curve from this survey (other examples: power-law, logarithmic, hyperbolic, etc.).
Linguistic Rules
- Morphological Rule Induction is an area of NLP focused on extracting morphological inflection rules from data (e.g., "add -s to pluralize nouns in English" or "change -er or -ons for first person plural present tense verbs in French"). Such rules could be useful language-specific features in the SLAM task. See the ACL's SIGMORPHON archives for some inspiration.
- Syntactic Rule Induction (e.g., "adjectives come before the noun in English, but after the noun in Spanish") could also yield other useful features to consider.
Grammatical Error Detection & Correction
- SLA modeling bears some similarity to GED and GEC research (e.g., CoNLL-13 and CoNLL-14 shared tasks). For example, both try to predict token-level errors, and successful methods might employ sequence models like HMMs, CRFs, or RNNs.
- However, SLA modeling is in some sense the opposite of GED or GEC: given a correct sentence, the goal of this task is to predict where a student is likely to make mistakes (based on their learning history).
Multi-Task Learning
- Teams who wish to compete in all three tracks (which is encouraged!) might view each track (language) as a variant of a single over-arching task. For example, this is sometimes used in multi-language machine translation (Dong et al., 2015). This is part of why we provide dependency parse features in the language-agnostic Universal Dependencies format.
- Similarly, one might also view each user as a different variant of a single over-arching task. A common example of this is personalized spam filtering (Attenberg et al., 2009).
Combined Regression & Ranking
- Systems will be evaluated using both AUC (a ranking metric) and F1 (a classification metric), which are not necessarily aligned. You may wish to compare system variants that optimize for one or the other or both. For linear models, Sculley (2010) presents a simple framework for combined regression and ranking.