2020 Duolingo Shared Task
STAPLE: Simultaneous Translation And Paraphrase for Language Education
This challenge is in conjunction with the WNGT workshop at ACL 2020.
Introduction
Machine translation systems typically produce a single output, but in certain cases, it is desirable to have many possible translations of a given input text. This situation is common with Duolingo (the world's largest language-learning platform), where some learning happens via translation-based exercises, and grading is done by comparing learners' responses against a large set of human-curated acceptable translations. We believe the processes of grading and/or manual curation could be vastly improved with richer, multi-output translation + paraphrase systems.
In this shared task, participants start with English prompts and generate high-coverage sets of plausible translations in five other languages. For evaluation, we provide sentences with handcrafted, field-tested sets of possible translations, weighted and ranked according to actual learner response frequency. We will also provide high-quality automatic translations of each input sentence that may (optionally) be used as a reference/anchor point, and also serves as a strong baseline. In this way, we expect the task to be of interest to diverse researchers in machine translation, MT evaluation, multilingual paraphrase, and language education technology fields.
Novel and interesting research opportunities in this task:
- A large set of sentences with comprehensive translations (though not exhaustive, per se)
- Translations weighted by real language-learner data
- Datasets in 5 language pairs.
The outcomes of this shared task will be:
- New translation datasets provided to the community
- New benchmarks for MT and paraphrasing
Take note of the task timeline below. Quick links:
- Mailing list for updates & announcements
- Data sets at Dataverse
- Baseline starter code at GitHub
- Official submissions & results at CodaLab
Official Results
(Updated May 26, 2020) The table below shows the overall results on the TEST set for each language, in terms of weighted F1. We have omitted results that did not outperform the baselines. More detailed results can be found in this spreadsheet.
These results differ slightly from the CodaLab leaderboard. CodaLab chooses to display a results from a team's entire submission (according to some comparison function). We have chosen to select each team's highest performing score for each language track, which are not necessarily all from the same submission.
Read the 2020 STAPLE Task Overview Paper »
| user | hu | ja | ko | pt | vi |
|---|---|---|---|---|---|
| jbrem | 0.555 | 0.318 | 0.404 | 0.552 | 0.558 |
| nickeilf | -- | -- | -- | 0.551 | -- |
| rakchada | 0.552 | -- | -- | 0.544 | -- |
| jspak3 | -- | -- | 0.312 | -- | -- |
| sweagraw | 0.469 | 0.294 | 0.255 | 0.525 | 0.539 |
| masahiro | -- | 0.283 | -- | -- | -- |
| mzy | -- | 0.260 | -- | -- | -- |
| dcu | -- | -- | -- | 0.460 | -- |
| jindra.helcl | 0.435 | 0.213 | 0.206 | 0.412 | 0.377 |
| darkside | -- | 0.194 | -- | -- | -- |
| nagoudi | -- | -- | -- | 0.376 | -- |
| baseline_aws | 0.281 | 0.043 | 0.041 | 0.213 | 0.198 |
| baseline_fairseq | 0.124 | 0.033 | 0.049* | 0.136 | 0.254* |
Important Dates
| July 10, 2020 | Workshop at ACL — VIRTUAL (Link, Registration)! |
| May 18, 2020 | Camera-ready system papers due |
| May 4, 2020 | System paper reviews returned |
| April 13 April 22, 2020 | Draft system papers due (SoftConf START) |
| April 8 April 16, 2020 | Final results announcement |
| April 6 April 13, 2020 | Final predictions deadline |
| March 30, 2020 | Data release (phase 3): blind TEST set (Dataverse, CodaLab) |
| March 2, 2020 | Data release (phase 2): blind DEV set (Dataverse, CodaLab) |
| January 13, 2020 | Data release (phase 1): TRAIN set + starter code (Dataverse, GitHub) |
Mailing List & Organizers
We have created a Google Group to foster discussion and answer questions related to this task:
Join the STAPLE Shared Task group »
The task organizers (all from Duolingo) are:
Task Definition & Data
Background
Duolingo is a free, award-winning, online language learning platform. Since launching in 2012, more than 300 million students from all over the world have enrolled in one of Duolingo's 90+ game-like language courses, via the website or mobile apps. For comparison, that is more than the total number of students in the entire U.S. school system.
A portion of learning on Duolingo happens through translation-based exercises. In this task, we focus on the challenges where users are given a prompt in the language they are learning (English), and type a response in their native language. Some examples of this are shown in the following images, which are taken from English lessons for Portuguese speakers.

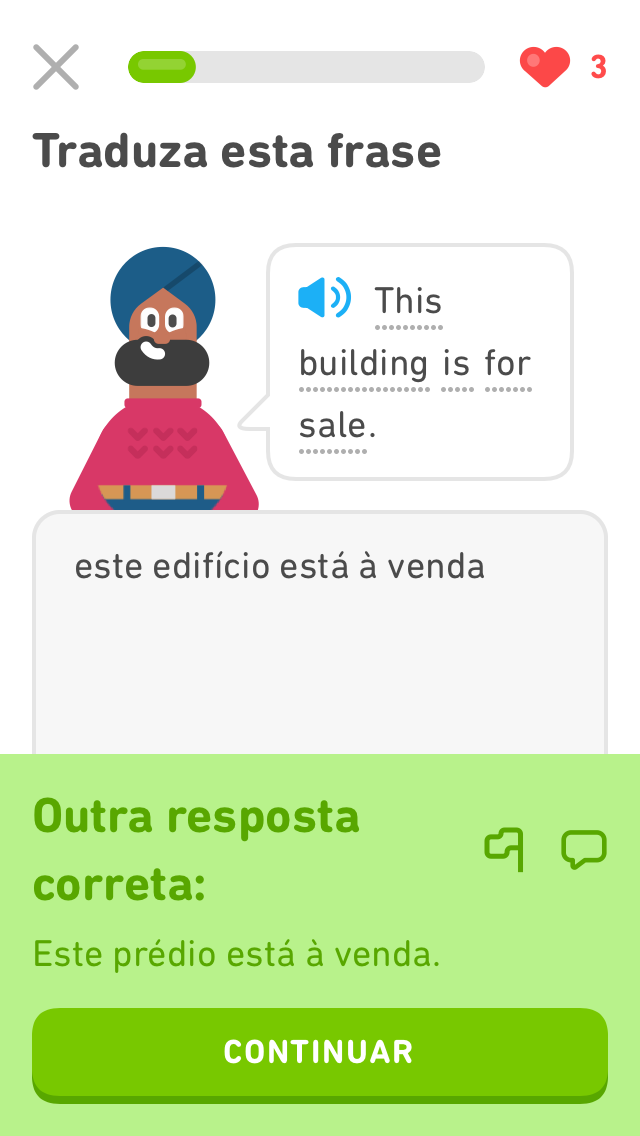
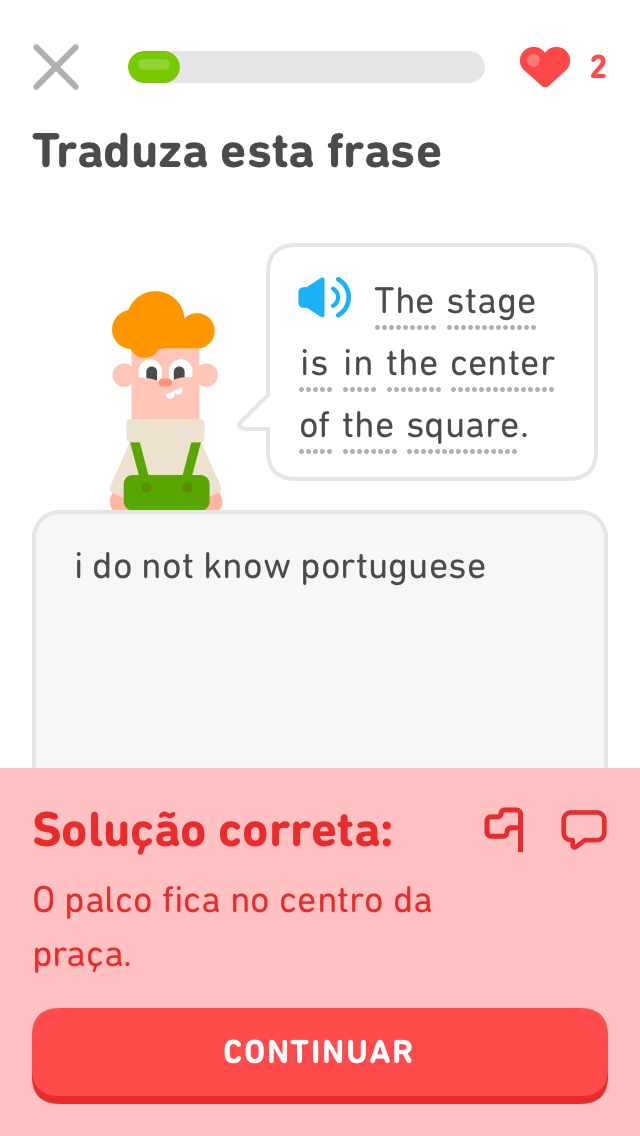
Prediction Task
Participants are given an English sentence, and are required to produce a high-coverage set of translations in the target language. In order to level the playing field, we also provide a high-quality automatic reference translation (via Amazon), which may be considered as a strong baseline for the machine translation task.
The prompt sentences come from Duolingo courses, and are often relatively simple (and a little quirky). For example, below is a sentence taken from the course that teaches English to Portuguese speakers:
| INPUT: Prompt | is my explanation clear? |
| INPUT: Reference Translation (from Amazon) | a minha explicação está clara? |
| OUTPUTS: Accepted Translations |
minha explicação está clara? minha explicação é clara? a minha explicação está clara? a minha explicação é clara? minha explanação está clara? está clara minha explicação? minha explanação é clara? a minha explanação está clara? é clara minha explicação? a minha explanação é clara? está clara a minha explicação? é clara a minha explicação? está clara minha explanação? é clara minha explanação? está clara a minha explanação? é clara a minha explanação |
Examining these data, it’s clear that not all accepted translations are equally likely, and therefore, they should be scored accordingly. As stewards of the world's largest and most comprehensive corpus of language learning data, we are able to use lesson response data to estimate which translations are more likely. This is used in the metric, described below.
Data
The data for this task comes from five Duolingo courses. All use English prompts, with multiple translations, although weighted by frequency from speakers of each of the following languages:
en_pt— Portugueseen_hu— Hungarianen_ja— Japaneseen_ko— Koreanen_vi— Vietnamese
The TRAIN data will include comprehensive accepted translations along with weights for participating teams to use in tuning their systems.
Statistics for the released training data are below. All dev and test sets have the same number of prompts (500). The training sets are sampled from each course.
| Language | TRAIN (prompts / total accepted) | DEV (prompts / total accepted) | TEST (prompts / total accepted) |
|---|---|---|---|
| en_hu | 4000 / 251442 | 500 / 27647 | 500 / 33578 |
| en_pt | 4000 / 526466 | 500 / 60294 | 500 / 67865 |
| en_ja | 2500 / 855941 | 500 / 172817 | 500 / 165095 |
| en_ko | 2500 / 700410 | 500 / 140353 | 500 / 150477 |
| en_vi | 3500 / 194720 | 500 / 29637 | 500 / 28242 |
Data Format
The provided data takes the following format. The weights on each translation correspond to user response rates. These weights are used primarily for scoring. You are not required to output weights.
prompt_65c64c31d672de7ed6e084757731dc60|is my explanation clear?
minha explicação está clara?|0.2673961621319991
minha explicação é clara?|0.16168857102956694
a minha explicação está clara?|0.11109168316077477
a minha explicação é clara?|0.08778538443694518
minha explanação está clara?|0.05717261411615019
está clara minha explicação?|0.04428213944745337
minha explanação é clara?|0.039226356284927835
a minha explanação está clara?|0.03634909976199087
é clara minha explicação?|0.03634909976199087
a minha explanação é clara?|0.03134646169709749
está clara a minha explicação?|0.03134646169709749
é clara a minha explicação?|0.02482689683978721
está clara minha explanação?|0.021938622406362747
é clara minha explanação?|0.021938622406362747
está clara a minha explanação?|0.018174549880995435
é clara a minha explanação?|0.009087274940497717
prompt_5665133396132783ba2fd30154c44ab0|this is my fault.
isto é minha culpa.|0.17991478900352792
isso é minha culpa.|0.1066452360752243
esta é minha culpa.|0.08944224863255358
isto é culpa minha.|0.07794622755249994
é minha culpa.|0.06803540456185586
essa é minha culpa.|0.05366296741002944
isso é culpa minha.|0.051089244145498244
isto é minha falta.|0.050195911419120616
esta é minha falta.|0.048348968383120375
isto é minha falha.|0.033156827981514404
essa é minha falha.|0.03157472903245173
essa é minha falta.|0.029874968047888008
esta é minha falha.|0.028026587883284097
isso é minha falha.|0.02366145043686166
isto é meu erro.|0.020908759965896084
isso é minha falta.|0.020908759965896084
isso é meu erro.|0.017321383900555543
isto é falha minha.|0.017321383900555543
isso é falha minha.|0.008660691950277771
isso é erro meu.|0.008660691950277771
isto é um erro meu.|0.008660691950277771
é minha falha.|0.008660691950277771
isso é um erro meu.|0.008660691950277771
isto é erro meu.|0.008660691950277771
Submission & Evaluation
Starter Code
You can find starter code here: https://github.com/duolingo/duolingo-sharedtask-2020/. This contains code to train standard seq2seq models, as well as the official scoring function, and some data readers.
Metrics
The main scoring metric will be weighted macro \(F_1\), with respect to the accepted translations. In short, systems are scored based on how well they can return all human-curated acceptable translations, weighted by the likelihood that an English learner would respond with each translation.
In weighted macro \(F_1\), we calculate weighted \(F_1\) for each prompt \(s\), and take the average over all prompts in the corpus. We chose to calculate precision in an unweighted fashion, and weight only recall. Specifically, for weighted true positives (WTP) and weighted false negatives (WFN), we have:
\[ \text{WTP}_s = \sum_{t \in TP_s} \text{weight}(t) \] \[ \text{WFN}_s = \sum_{t \in FN_s} \text{weight}(t) \] \[ \text{Weighted Recall}(s) = \frac{\text{WTP}_s}{\text{WTP}_s + \text{WFN}_s} \]The weighted \(F_1\)'s are then averaged over all prompts in the corpus.
\[ \text{Weighted Macro } F_1 = \sum_{s \in S} \frac{\text{Weighted }F_1(s)}{|S|} \]Evaluation: CodaLab
All system submissions and evaluation will be done via CodaLab. There will be a DEV phase where you can submit predictions online after the phase 2 data release, and a TEST phase for final evaluation after the phase 3 data release. Check for more details as the submission deadline approaches.
Prediction Format
The submission file format is similar to the Amazon Translate prediction file.
Submission should have blocks of text separated by one empty line, where the first line of the block is an ID and prompt, and all following lines are unique predicted paraphrases, order doesn't matter. During evaluation, the punctuation will be stripped, and all text lowercased.
Here is an example prediction file, with prompts corresponding to the example above:
prompt_65c64c31d672de7ed6e084757731dc60|is my explanation clear? minha explicação está clara? minha explicação é clara? a minha explicação está clara? a minha explicação é clara? an obviously incorrect prediction! prompt_5665133396132783ba2fd30154c44ab0|this is my fault. isto é minha culpa. isso é minha culpa. esta é minha culpa. isto é culpa minha. é minha culpa. essa é minha culpa. isso é culpa minha. isto é minha falta. esta é minha falta. isto é minha falha. essa é minha falha. my bad.
System Papers & Citation Details
All teams are expected to submit a system paper describing their approach and results, to be published in the workshop proceedings and available through the ACL Anthology website. Please do so even if you are unable to travel to the ACL conference in July 2020.
Note that we are interested not only in top-performing systems (i.e., metrics), but also meaningful findings (i.e., insights for language and/or learning). Teams are encouraged to focus on both in their write-ups!
Papers should follow the the ACL 2020 submission guidelines. Teams are invited to submit a full paper (4-8 pages of content, with unlimited pages for references). We recommend using the official style templates:
All submissions must in PDF format and should not be anonymized. Supplementary files (hyperparameter settings, external features or ablation results too extensive to fit in the main paper, etc.) are also welcome, so long as they follow the ACL 2020 Guidelines. Final camera ready versions of accepted papers will be given up to one additional page of content (9 pages plus references) to address reviewer comments. Papers must include the following citation:
Stephen Mayhew, Klinton Bicknell, Chris Brust, Bill McDowell, Will Monroe, and Burr Settles. 2020. Simultaneous Translation And Paraphrase for Language Education. In Proceedings of the ACL Workshop on Neural Generation and Translation (WNGT), ACL.
@inproceedings{staple20,
Author = {Stephen Mayhew and Klinton Bicknell and Chris Brust and Bill McDowell and Will Monroe and Burr Settles},
Booktitle = {Proceedings of the ACL Workshop on Neural Generation and Translation (WNGT)},
Publisher = {ACL},
Title = {Simultaneous Translation And Paraphrase for Language Education},
Year = {2020}}
Submit your paper through START »
\aclfinalcopy line is uncommented, and that the final
PDF includes author names and contact information.
Tips, Resources, & Related Work
The following resources may prove useful. We may update this section as the challenge progresses....
Translation
- fairseq is a Pytorch-based framework for sequence modeling, such as machine translation or text generation.
- KyTea may be useful for segmentation in Japanese.
- Multilingual contextual models, many of which are available through HuggingFace transformers.
- Multilingual BERT has proven to be remarkably useful for cross-lingual applications.
- XLM (Lample & Conneau, 2019), and XLM-R (Conneau et al., 2019), by virtue of parallel text in training, may outperform Multilingual BERT.
- It may be important to maintain a diverse beam when decoding (Ippolito et al., 2019).
- Given the nature of the data, phrase-based systems such as Giza++, Moses, and others may in fact be competitive with more modern, neural methods (see statmt.org for many resources)
MT Evaluation
- In the HyTer metric (Dreyer & Marcu, 2012), a translation prediction is scored against a comprehensive list of manually-gathered translations. Our evaluation is similar in the sense that we have high-coverage translation options at test time, but the goals are slightly different. Where HyTer is concerned with accurate measurement of machine translation, this task pursues high-coverage output. We also provide real-world weights with each translation option.
- Where HyTer employed humans in writing all possible translations of a sentence, Automated HyTer (Apidianaki et al., 2018) uses the Paraphrase Database (PPDB).
Paraphrasing
- The Multilingual Paraphrase Database (PPDB) may prove useful (Ganitkevitch & Callison-Burch, 2014)
- Towards Universal Paraphrastic Sentence Embeddings (Wieting et al., 2015)
- Simple and Effective Paraphrastic Similarity from Parallel Translations (Wieting et al, 2019)
- Learning to Paraphrase: An Unsupervised Approach Using Multiple-Sequence Alignment (Barzilay & Lee, 2003)